
-
cubrid compactdb 유틸리티는 데이터베이스
볼륨 중 사용되지 않는 공간을 확보하기 위해 사용
-
CUBRID는 객체를 삭제할 경우 삭제된 객체를
참조하는 다른 객체가 있을 수 있기 떄문에 삭제된 객체에 대한 OID는 바로 사용 가능한 빈 공간이
될 수 없음. 이 때 cubrid compactdb 유틸리티를
수행하면 삭제된 객체에 대한 참조를 NULL로 표시하는데, 이렇게
NULL로 표시된 공간은 OID가 재사용할 수 있는 공간임을
의미함.
2.
compactdb 사용 모드
-
데이터베이스 서버가 정지된 경우(offline)에는
독립 모드(stand-alone mode)로, 데이터베이스
서버가 구동 중인 경우(online)에는 클라이언트 서버 모드(client-server
mode)로 수행.
-
각각의 모드에 대해서 사용할 수 있는 옵션의 차이가 있으며, 자세한 내용은 아래에서 설명하도록 하겠습니다.
3.
compactdb 구문과 옵션
① 구문 : cubrid copactdb [<options>] database_name [ class_name1, class_name2, …]
-
cubrid : 큐브리드 서비스 및 데이터베이스
관리를 위한 통합 유틸리티
-
compactdb : 대상 데이터베이스에 대하여
삭제된 데이터에 할당되었던 OID가 재사용될 수 있도록 공간을 정리하는 명령
-
database_name : 공간을 정리할 데이터베이스의
이름
- class_name_list : 공간을 정리할 테이블 이름 리스트를 데이터베이스 이름 뒤에 직접 명시할 수 있으며, -i 옵션과 함께 사용할 수 없다. 클라이언트/서버 모드에서만 명시할 수 있다.
②
옵션
|
옵션 |
내용 |
기본값 |
사용 모드 |
|
-v, --verbose |
어느 클래스가 현재
정리되고 있는지 등의 진행 상황에 대한 메시지를 화면에 출력 |
- |
Standalone, Client/Server |
|
-S, --SA-mode |
데이터베이스 서버가
구동 중단된 상태에서 독립 모드(standalone)로 수행하기 위함 |
-C |
Standalone |
|
-C, --CS-mode |
데이터베이스 서버가
구동 중인 상태에서 클라이언트/서버 모드로 수행하기 위함 |
-C |
Client/Server |
|
-i,
--input-class-file=FILE |
대상 테이블 이름을
포함하는 입력 파일 이름을 지정할 수 있다. 라인 당 하나의 테이블 이름을 명시하며, 유효하지 않은 테이블 이름은 무시된다. |
- |
Client/Server |
|
-p,
--pages-commited-once=NUMBER |
한 번에 커밋할 수
있는 최대 페이지 수를 지정. 최소 값은 1, 최대 값은
10이다. 옵션 값이 작으면 클래스/인스턴스에 대한 잠금 비용이 작으므로 동시성은 향상될 수 있으나 작업 속도는 저하될 수 있고, 옵션 값이 크면 동시성은 저하되나 작업 속도는 향상될 수 있음 |
10 |
Client/Server |
|
-d,
--delete-old-repr |
카탈로그에서 과거 테이블
표현(스키마 구조)을 삭제할 수 있다. ALTER
문에 의해 칼럼이 추가되거나 삭제되는 경우 기존의 레코드에 대해 과거의 스키마를 참조하고 있는 상태로 두면, 스키마를 업데이트 하는 비용을 들이지 않기 때문에 평소에는 과거의 테이블 표현을 유지하는 것이 좋다. |
- |
Client/Server |
|
-I, --
Instance-lock-timeout=NUMBER |
인스턴스 잠금 타임아웃
값을 지정. 최소 값은 1, 최대 값은 10이다. 설정된 시간동안 잠금
인스턴스를 대기하므로, 옵션 값이 작을수록 작업 속도는 향상될 수 있으나 처리 가능한 인스턴스 개수가
적어진다. 반면, 옵션 값이 클수록 작업 속도는 저하되나 더 많은 인스턴스에 대해 작업을 수행할 수 있다. |
2 |
Client/Server |
|
-c,
--class-lock-timeout=NUMBER |
클래스 잠금 타임아웃
값을 지정. 최소값은 1, 최대 값은 10이다. 설정된 시간동안 잠금
테이블을 대기하므로, 옵션 값이 작을수록 작업 속도는 향상될 수 있으나 처리 가능한 테이블 개수가
적어진다. 반면, 옵션 값이 클수록 작업 속도는 저하되나 더 많은 테이블에 대해 작업을 수행할 수 있다. |
10 |
Client/Server |
4.
compactdb 따라해보기
①
현재 데이터베이스 사용량 확인
- $ cubrid spacedb –s testdb
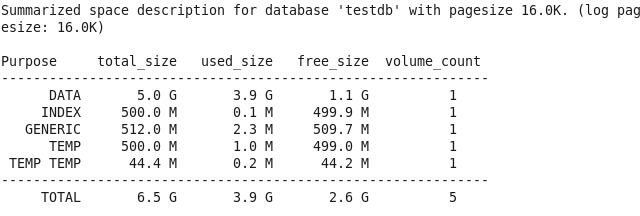
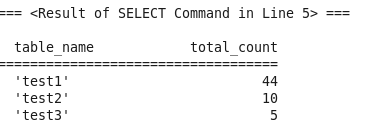
- 실제 테이블 건수(실제 테이블에는 많은 양의 데이터가 들어가 있지 않으나, 빈번한 delete, insert로 인해 데이터베이스 용량을 많이 차지하고 있음)
② vi 편집기로 compactdb 대상 테이블 입력
- $ vi table_list.txt
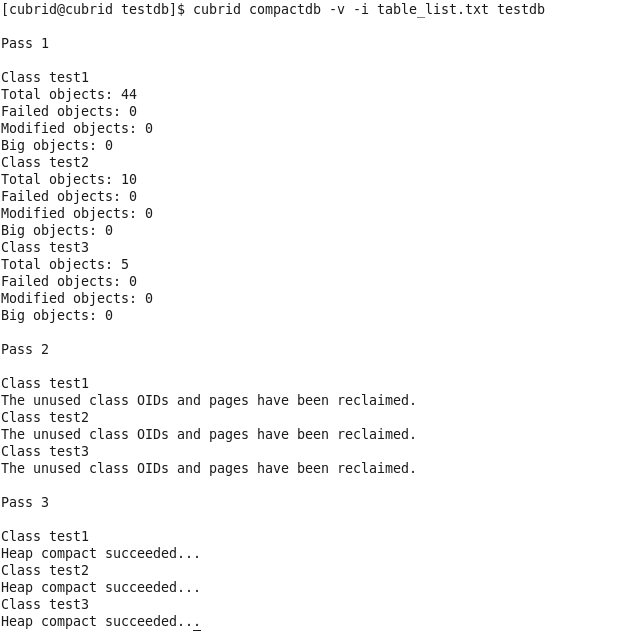
③ compactdb 수행
- $ cubrid compactdb –v –i table_list.txt testdb
④
데이터베이스 용량 확보 확인
- $ cubrid spacedb –s testdb
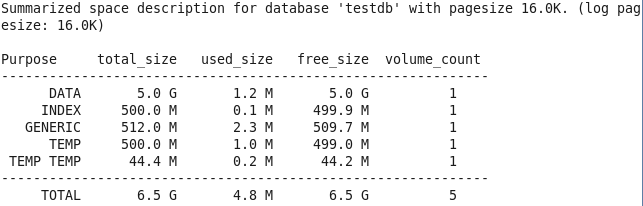
- 약 3.9G의 DATA 용량이 확보된걸 확인할 수 있음
5.
HA환경에서의
compactdb 사용법
①
Master 노드와 Slave 노드가 모두 정지된 경우(offline)
-
정상적으로 compactdb 작업을 수행할 수
있으나, - I, -i, -c, -d, -p 옵션을
사용할 수 없음
②
Master 노드와 Slave 노드가 모두 구동 중인 경우(online)
-
Master 노드에서는 정상적으로 compactdb 작업이 수행되나, Slave 노드는 수행되지 않음
-
전체 테이블에 대해 compactdb 작업을
수행할 경우 Slave 노드를 정지시킨 후 standalone 모드에서
–S 옵션을 사용하여 compactdb를 수행한다. 만약 데이터베이스 용량이 매우 크다면 Slave 노드의 compactdb 작업이 수행되는 동안 Master 노드에서는 데이터를
반영하지 못해 archive 로그를 삭제하지 못하기 때문에 그로 인해 발생할 수 있는 Disk Full을 주의하여야 한다.
-
일부 테이블에 대해 compactdb 작업을
수행하거나, 그 외 클라이언트/서버 모드에서만 사용할 수
있는 - I,
-i, -c, -d, -p 옵션을 사용해야 할 경우 Fail-over를 진행하여 Slave 노드를 Master 노드로 변경한 후 compactdb 작업을 진행한다.
 리눅스에서 top 명령어를 통한 CPU 점유율 확인 및 측정하기
리눅스에서 top 명령어를 통한 CPU 점유율 확인 및 측정하기