
이 튜토리얼은 저번 ERwin을 이용한 CUBRID 리버스 엔지니어링에 이어 두번째 ERwin을 이용한 포워드 엔지니어링입니다.
여기서는 데이터 모델을 포워드 엔지니어링하고 실제 데이터베이스에 적용하는 방법을 설명합니다.
" ERwin 용어로 Forward Engineering은 LDM (Logical Data Model)을 ERwin Data Modeler에서 실제 데이터베이스의 PDM (Physical Data Model)으로 변환하는 프로세스입니다. "
ERwin을 설치 후 (이 튜토리얼에서는 2020 R2 14677 버전을 이용합니다) 프로그램을 실행 후 메인 메뉴에서 File -> New...을 선택합니다.
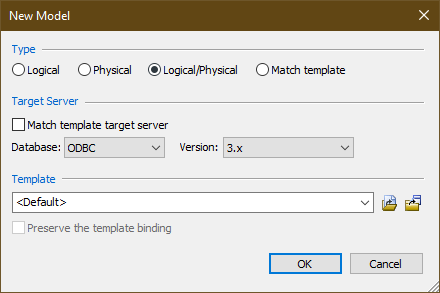
리버스 엔지니어링과 같이, New Model 창이 열리면, 타입과 대상 서버를 다음과 같이 선택한 후 OK 버튼을 선택합니다. (큐브리드 ODBC 드라이버는 ODBC Spec 3.x 기반으로 구현됨)
엔터티 만들기
ERwin 언어에서 Entity는 테이블 오브젝트입니다. 테이블 표현을 만들려면 상단의 기본 도구 모음에서 엔티티 도구를 선택합니다.
그런 다음 작업 공간의 아무 곳이나 클릭합니다. 새 테이블 객체가 자동으로 배치됩니다. 텍스트 필드에 이름을 입력한 후 키보드의 Tab 키를 눌러 키 섹션으로 이동하여 기본 키를 추가합니다. Tab 키를 다시 눌러 다음 섹션으로 이동하여 다른 컬럼을 입력합니다. 같은 유형의 컬럼을 더 입력하려면 키보드에서 Enter 키를 누르면 됩니다. 모든 컬럼을 입력 한 후 Esc 키를 눌러 작업을 완료합니다.
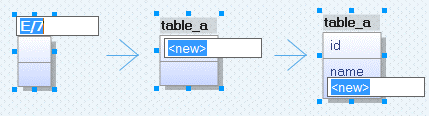
이 튜토리얼에서는 table_a 와 table_b라는 두 개의 테이블을 작성하고 이를 기존 demodb 데이터베이스로 전달합니다.

컬럼 속성 설정
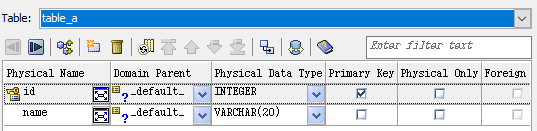
테이블과 필요한 컬럼을 만든 후에는 각 컬럼에 데이터 타입과 기타 속성을 설정해야합니다. 그러기 위해 아무 컬럼을 두 번 클릭합니다. 부모 도메인, 데이터 타입을 선택하고 컬럼이 기본 또는 외래키인지 확인합니다. 모든 테이블에 대해 반복하면 됩니다.
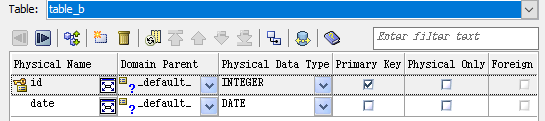
엔터티 관계
ERwin에는 여러 타입의 관계가 있습니다. 이 예 에서는 식별 관계 및 비식별 관계를 설명합니다.
- 식별 관계
이 두 가지 관계 유형의 큰 차이점은 아래의 예제 또는 demodb 예제의 결과에서 볼 수 있듯이 식별 관계 유형의 외래 키는 복합키 (여러 컬럼으로 정의 된 PK)의 일부로 자동으로 추가된다는 것입니다.
즉, “식별 관계는 하위 엔티티의 인스턴스가 상위 엔티티와의 연관을 통해 식별되는 두 엔티티 사이의 관계입니다. 이는 하위 엔티티는 식별을 위해 상위 엔티티에 의존하고 상위 엔터티 없이는 존재할 수 없음을 의미합니다. 식별 관계에서 상위 엔티티의 한 인스턴스는 하위의 여러 인스턴스와 관련됩니다. (ERwin 문서)”
따라서 복합키의 일부인 외래 키를 생성하려면 Identifying Relationship 를 선택합니다. 이를 위해 기본 도구 모음에서 식별 관계 도구를 선택합니다.
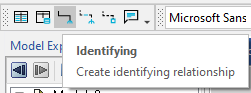
table_b에서 table_a를 참조해야하므로 (외래 키는 table_b에서 생성됨) 식별 관계 도구를 선택한 후에 먼저 table_a를 클릭 한 다음 table_b를 클릭하거나 table_a를 클릭하고 table_b로 드래그합니다. 참조하는 테이블에 참조되는 테이블의 기본 키와 동일한 이름의 컬럼이 이미 포함 된 경우 (이 경우 컬럼 ID가 두 테이블에 모두 존재하는 경우) 프로그램은 Key Migration Conflict 창을 팝업합니다.
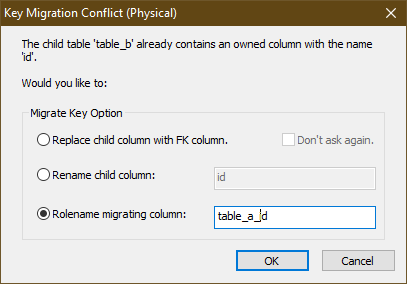
두 테이블 모두에 고유한 ID 컬럼이 있고 하위 속성을 바꾸고 싶지 않기 때문에 Rolename migrating attribute을 선택하고 사용자 지정 외래 키 컬럼 이름을 입력합니다. 그런 다음 OK 버튼을 클릭합니다. 새 외래 키 컬럼이 추가되어 복합키의 일부가 된 것을 볼 수 있습니다.

- 비 식별 관계
이제 동일한 단계를 수행하지만 외래 키에 대해 비 식별 관계를 선택하고 어떤 모델이 생성되는지 확인합니다. 이를 위해 기본 도구 모음에서 비 식별 관계 도구를 선택합니다. 여기서 비 식별 관계 도구는 점선으로 표시되고 식별 관계 도구는 실선으로 표시됩니다.
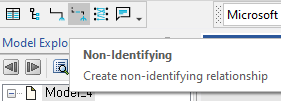
이전과 마찬가지로 table_a를 클릭하고 마우스를 table_b로 드래그합니다. 또한 ID 컬럼 이름 충돌을 해결하기 위해 Rolename migrating attribute을 선택하고 table_a_id와 같은 사용자 지정 외래 키 컬럼 이름을 입력하십시오. 그런 다음 OK 버튼을 클릭합니다. 이제 외래 키가 더 이상 복합키에 속하지 않는다는 점에서 모델이 이전 모델과 다릅니다.

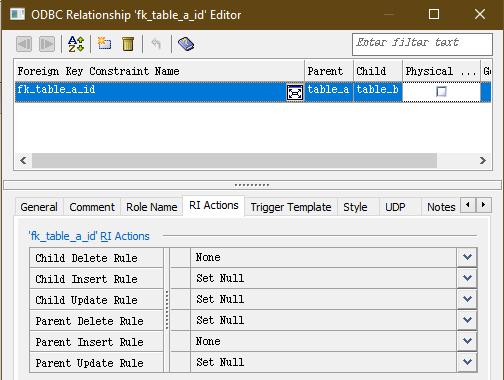
작업을 완료하기 위해 이 두 테이블 사이의 관계 선을 두 번 클릭하여 ON UPDATE 또는 ON DELETE 참조 무결성 규칙 또는 이 외래 키 색인의 이름과 같은 외래 키 속성을 변경할 수 있습니다. 이 경우 제약 조건 이름을 fk_table_a_id로 설정하고 아래 표시된대로 RI 동작을 설정합니다.
" CUBRID의 인덱스 이름은 테이블마다 고유하므로 임의의 두 테이블이 동일한 인덱스 이름을 가질 수 있습니다. 따라서 CUBRID에서는 다른 테이블 이름이나 다른 식별자와 중복을 피하기 위해 fk_col_name과 같은 인덱스에 간단하고 명확한 이름을 지정해야 합니다. 자세한 내용은 매뉴얼을 참조하십시오. "
포워드 엔지니어링 데이터 모델
이제 새로 생성 된 데이터 모델을 기존 demodb 데이터베이스로 엔지니어링을 진행합니다.
- 스키마 미리보기
Actions -> Forward Engineer... -> Schema... 을 선택합니다. 만약 이 메뉴가 활성화 되어있지 않다면, Logical Model을 보고 있는 것입니다. Physical Mode로 바꾸기 위해 다음과 같이 변경합니다. 변경하면 메뉴가 활성화될 것입니다.
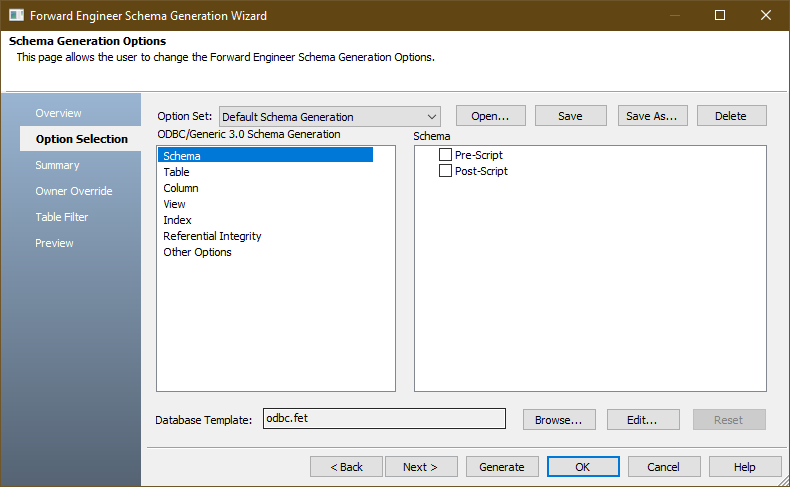
데이터베이스 서버에서 실행될 스크립트를 미리 보려면 사이드 메뉴 하단에있는 Preview 탭을 누르십시오. 필요한 경우 여기에서 SQL을 수동으로 수정할 수 있습니다.
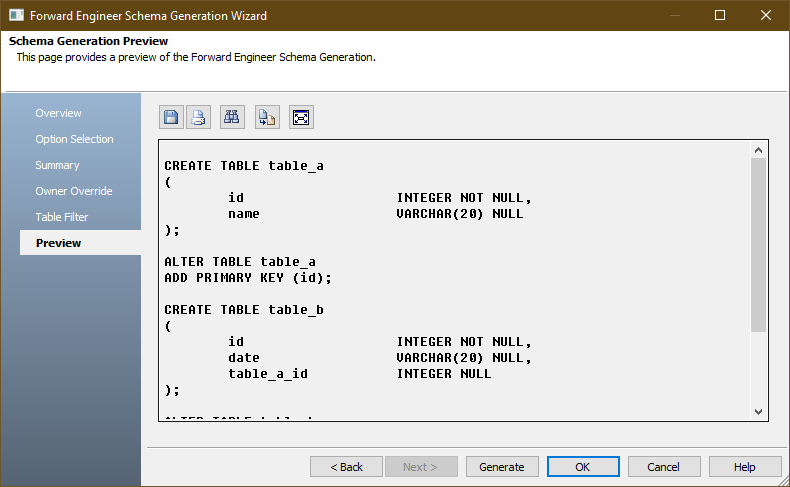
- 예약어 사용
이 예에서 table_b에 date라는 이름의 컬럼이 포함되어 있음을 알 수 있습니다. CUBRID에서 date는 DATE 데이터 타입을 나타내는 예약어이다. 따라서 위의 지정된 스크립트를 직접 실행하려고하면 다음과 같은 오류가 발생합니다.
[CUBRID][ODBC CUBRID Driver][-493]Syntax: syntax error, unexpected Date, expecting CHECK or FOREIGN or PRIMARY or UNIQUE Execution Failed!
예약어와 이름이 같은 컬럼이 필요할 때 오류를 해결하려면 이러한 컬럼 이름을 백틱 (``) 또는 큰 따옴표 ( "") 또는 대괄호로 감싸면 됩니다. ([]). 예약어에 대한 자세한 내용은 CUBRID 매뉴얼의 예약어 섹션을 참고하십시오.
ERwin은 각 컬럼 이름을 수동으로 수정하는 대신 자동으로 Quote Names 해주는 옵션을 제공합니다. 이 옵션은 Preview 탭을 누르기 전에 Summary 탭을 클릭하고 Edit Option에서 Quote Names 옵션을 체크합니다. (기본값 : 선택하지 않음).
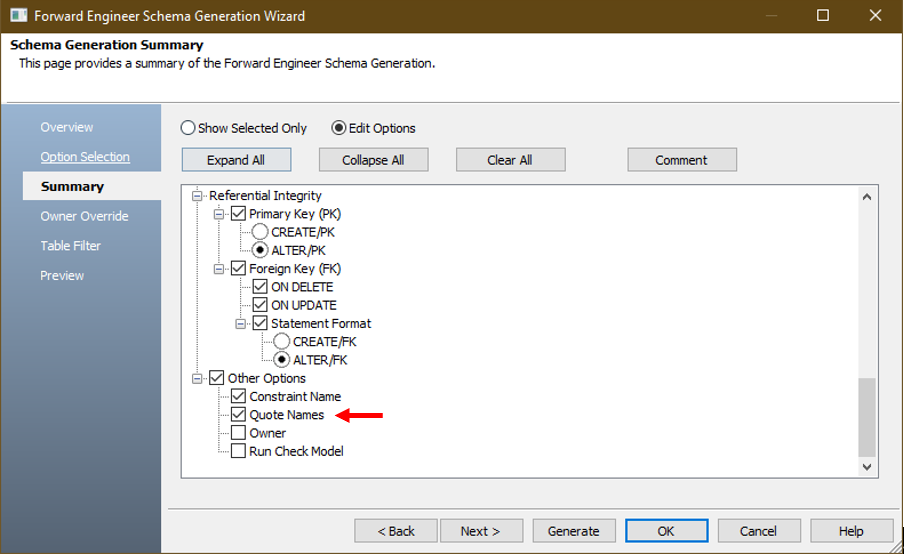
이제 Preview 탭을 다시 눌러 변경 사항을 확인합니다. 테이블 이름과 키 이름을 포함한 모든 식별자는 이제 큰 따옴표로 감싸 CUBRID 서버에서 실행할 수 있게 되었습니다.
확인 후 Generate... 버튼을 클릭합니다.
- 데이터베이스 연결 설정
리버스 엔지니어링과 마찬가지로 ODBC 연결 창이 뜨면 사용자 이름 및 비밀번호와 같은 데이터베이스 연결 정보를 입력하십시오. "CUBRID"가 ODBC Data Source 매개 변수의 값으로 자동 선택되지 않으면 이를 클릭하고 "CUBRID"를 선택한 다음 Connect 버튼을 클릭합니다.
모든 정보가 정확하면 성공했다는 메세지가 나타납니다.
" 여기서 중요한 점은 모든 명령문이 한번에 처리가 아니라 하나씩 띠러 실행된다는 것입니다. 즉, 명령문 중 하나가 중간에 실패해도 이전에 실행 성공한 명령문이 롤백되지 않습니다. "
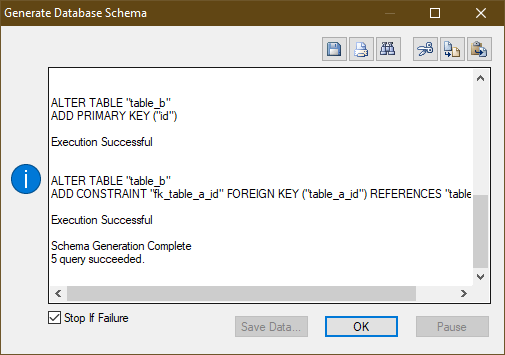
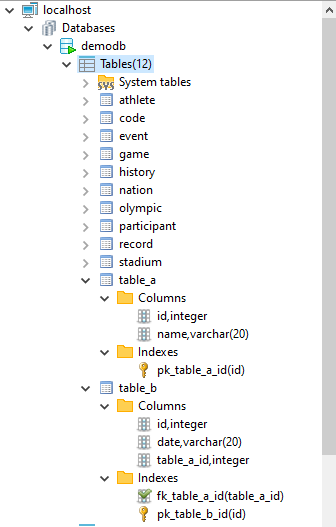
서버에서 올바르게 실행되었는지 확인하기 위해 CUBRID 용 GUI 데이터베이스 관리 도구 CUBRID Admin에서 테이블과 속성을 확인할 수 있습니다. 이제 두 테이블이 데이터베이스 내에 있고, 모든 컬럼이 존재하고 데이터 타입이 올바르며, PK 및 FK 제약 조건이 성공적으로 생성되었을 뿐만 아니라 테이블 및 컬럼 이름이 데이터 모델에서 설정 한 것과 같음을 확인할 수 있습니다.
- 기타 옵션
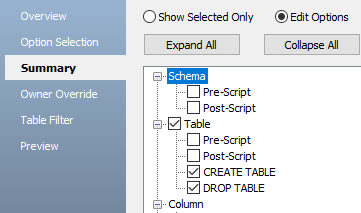
스키마를 생성하기 전에 수행할 수있는 작업은 DROP TABLE 옵션이 있습니다. 이 옵션은 대상 데이터베이스에 모델에서 생성할 테이블이 이미 존재할 경우 유용합니다. 이 옵션을 체크하면 Preview 창에서 만들려는 각 테이블에 대해 별도의 DROP TABLE 문을 볼 수 있습니다.
 ERwin을 이용한 CUBRID 리버스 엔지니어링
ERwin을 이용한 CUBRID 리버스 엔지니어링