CSQL에서 PreparedStatement 사용하여 Query Plan 확인하기
Prepare statement를 이용하여 값을 질의에 포함하지 않고 bind 했을 경우와 질의상에 값을 직접 포함하였을 경우,
일부 상황에서 값에 대한 해석이 모호해져 질의 플랜이 다르게 만들어져 질의의 성능이 달라지는 경우가 있습니다.
이를 위해 csql 에서 prepare statement 사용하는 방법을 정리하였습니다.
아래 확인 예시는 11.2 에서 해결된 부분이나, 그 이전 부분에서 질의 수행 계획이 달라졌음에 대한 이해를 위해 사용하였습니다.
CSQL에서 PreparedStatement 사용
|
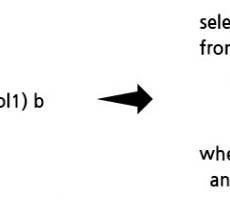
1. Prepared Statement 생성 PREPARE stmt_name FROM 'sql문';
2. Prepared Statement 실행 EXECUTE stmt_name [USING value, value2 ...];
3. Prepared Statement 해제 {DEALLOCATE | DROP} PREPARE stmt_name;
|
사용 예시(2가지)
|
1. csql > PREPARE pstmt FROM 'SELECT 1 + ?'; csql > EXECUTE pstmt USING 4; csql > DROP PREPARE pstmt;
|
|
2. csql > PREPARE pstmt FROM 'SELECT col1 + ? FROM tbl WHERE col2 = ?'; csql > SET @a=3, @b='abc'; csql > EXECUTE pstmt USING @a, @b; csql > DROP PREPARE pstmt;
|
preparedstatement 사용법의 자세한 내용은 아래 링크의 매뉴얼을 참고하세요.
https://www.cubrid.org/manual/ko/11.2/sql/query/prepare.html
Query Plan 확인 예시
|
csql >;trace on
|
|
1. BIND 사용
PREPARE pstmt FROM ' === <Result of SELECT Command in Line 1> === ~ 2 command(s) successfully processed. Query Plan: rewritten query: (select nvl(max( to_number( substr(tbla.id, 5))), 0) from tbla tbla where tbla.id like substr( ?:0 , 1, 3)|| cast('%' as varchar)) INDEX SCAN (tbla.idx1) (key range: tbla.id=a.id, covered: true) rewritten query: (select count(tbla.id) from tbla tbla where tbla.id=a.id) TABLE SCAN (a) rewritten query: select (select count(tbla.id) from tbla tbla where tbla.id=a.id), (select nvl(max( to_number( substr(tbla.id, 5))), 0) from tbla tbla where tbla.id like su
|
|
2. 상수 사용
SELECT === <Result of SELECT Command in Line 1> === ~ 1 command(s) successfully processed. Query Plan: rewritten query: (select nvl(max( to_number( substr(tbla.id, 5))), 0) from tbla tbla where (tbla.id>= ?:4 and tbla.id< ?:5 )) INDEX SCAN (tbla.idx1) (key range: tbla.id=a.id, covered: true) rewritten query: (select count(tbla.id) from tbla tbla where tbla.id=a.id) TABLE SCAN (a) rewritten query: select (select count(tbla.id) from tbla tbla where tbla.id=a.id), (select nvl(max( to_number( substr(tbla.id, 5))), 0) from tbla tbla where (tbla.id>= ?:4
|
위 예시 질의의 서로 다른 plan 문제는 현재(11.2) fix됨.
 CUBRID의 개발 문화: CUBRID DBMS 프로젝트 빌드 가이드와 빌드 ...
CUBRID의 개발 문화: CUBRID DBMS 프로젝트 빌드 가이드와 빌드 ...