서비스 가용성 향상을 위한 구성으로서, 하나의 마스터 노드와 하나의 슬레이브 노드로 이루어집니다.

PRODUCTS
Enterprise Open Source DBMS
CUBRID는 관계형 DBMS로서 엔터프라이즈 시장에서 요구하는 대용량 데이터 처리 능력 및 성능, 안정성, 가용성, 관리 편의성을 제공하고 있습니다. ANSI SQL을 준수하고 있으며, MVCC 기능, 고가용성을 위한 HA (High-Availability) 기능, Oracle/MySQL 호환성, DB 관리 및 마이그레이션을 위한 GUI 기반의 각종 도구를 제공하고 있습니다. CUBRID는 3-tier 구조를 이루는 응용(Application) - 브로커(Broker) - 서버(Server)로 구성되며, 유연하게 시스템을 구축할 수 있어 데이터가 급증하는 온라인 트랜잭션 처리(OLTP: On-line Transaction Processing) 서비스에 적합합니다.
주요 기능
고가용성(High Availability)
무정지 서비스를 위한 CUBRID HA
CUBRID는 DBMS 자체적으로 HA (High-Availability) 기능을 제공함으로써 서버 이중화를 통한 24시간 * 365일 무정지 서비스 구현이 가능합니다. HA 기능을 통한 이중화 구성을 통해 액티브 서버(마스터 노드)에 디스크, 네트워크 등 장애가 발생할 경우 스탠바이 서버(슬레이브 노드)가 자동절체(automatic fail-over)를 하여 무중단 서비스를 제공하고 있으며, 필요 시 레플리카(replica) 서버를 다중화하여
조회 서비스에 대한 부하를 분산할 수도 있습니다.
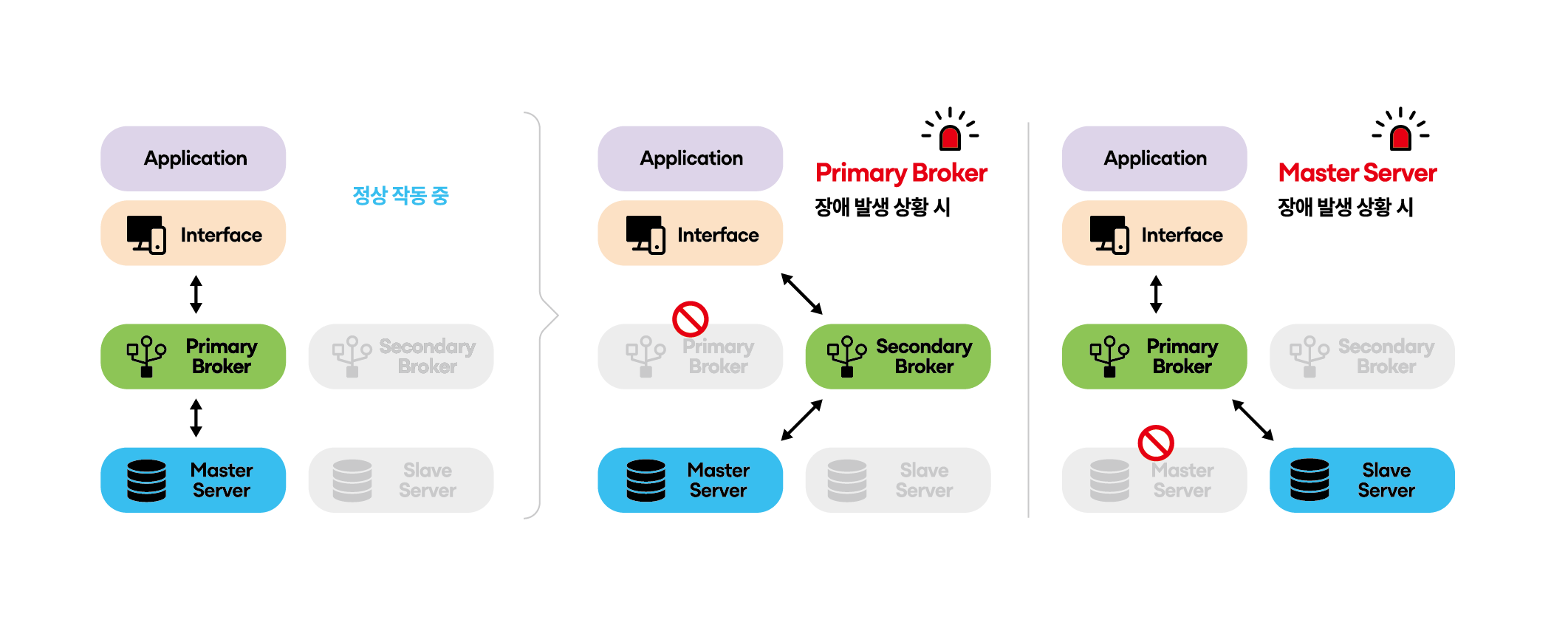
CUBRID HA 환경은 읽기/쓰기 부하를 담당하는 마스터 노드(Master Node)와 읽기 부하를 분산시키고 장애 시 마스터 기능을 대체하는 슬레이브 노드(Slave Node), 그리고 HA와는 관계 없이 부하 분산 기능을 담당하는 복제 노드(Replica Node)로 구성할 수 있습니다.
-
HA 기본 구성(M:S:R = 1:1:0)
-
HA 확장 구성(M:S:R = 1:N:0)
서비스 가용성 향상 및 부하를 분산시킬 수 있는 구성으로서, 하나의 마스터 노드와 N개의 슬레이브 노드로 이루어집니다. IDC 이중화 구성 역시 가능합니다.
-
부하 분산 구성(M:S:R = 1:1:N)
HA 기본 구성에 여러 개의 복제 노드를 추가하여 읽기(read) 부하를 분산시킬 수 있는 구성입니다. HA 확장 구성에 비해 마스터 노드의 부하가 적습니다.
최근에는 재해복구(DR: Disaster Recovery) 관련 IDC 이중화 요구가 발생하고 있으며, CUBRID HA 확장 구성을 통해 해결할 수 있습니다.
DBLINK
외부 데이터베이스의 조회를 위한 CUBRID DBLINK
CUBRID DBLink는 CUBRID 또는 이기종 DBMS의 데이터를 이용하여 조인 등의 복잡한 질의를 수행할 수 있는 기능을 제공합니다.
외부 데이터베이스의 정보를 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘합니다. 단 외부 데이터베이스를 여러 개 설정은 가능 하나, 정보를 조회할 때는 한 개의 타 데이터베이스의 정보만 조회할 수 있습니다.
CUBRID DBLink는 SELECT의 FROM절에 연결될 서버와 실행될 질의를 명시한 DBLINK 구문 형식과 원격 테이블 (테이블 확장명) 형식으로 사용 가능하며, INSERT/REPLACE/UPDATE/DELETE/MERGE구문은 원격 테이블 형식만 사용할 수 있습니다.
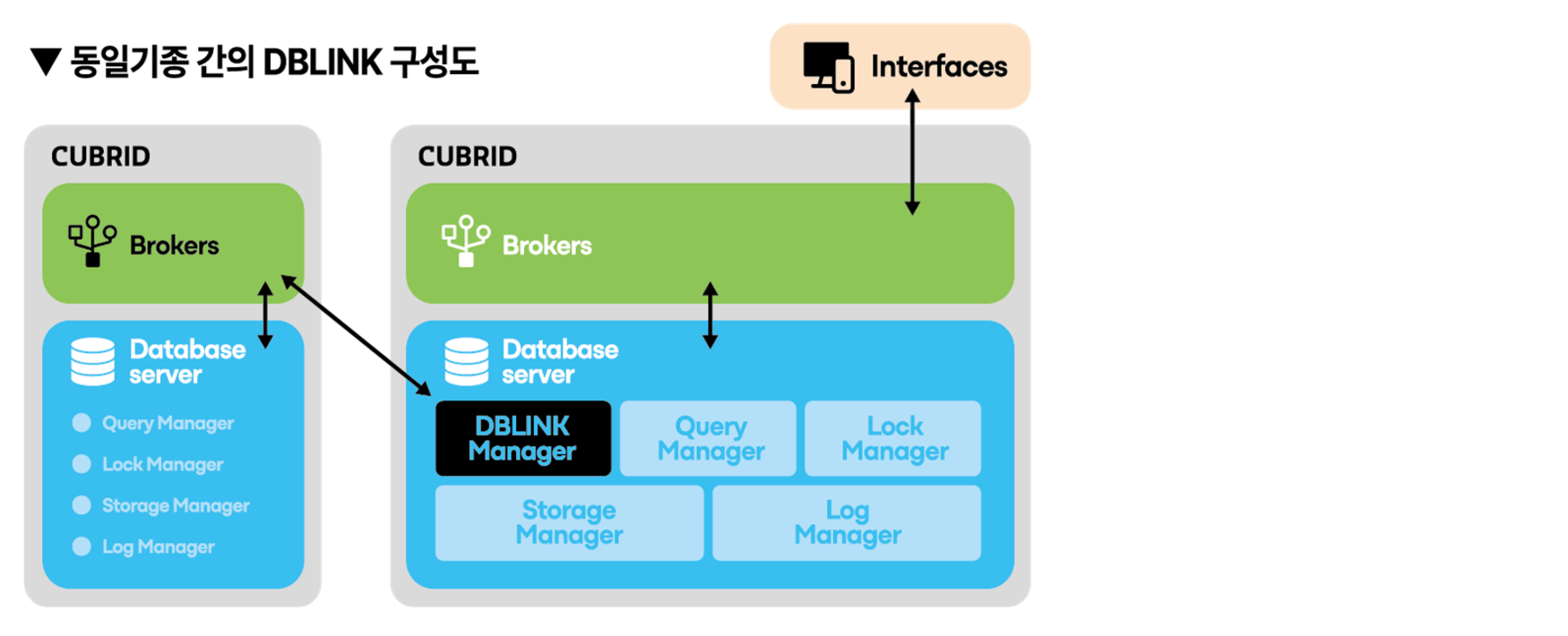
동일기종의 외부 데이터베이스의 정보를 조회하기 위한 구성도를 보면 Database Server에서 CCI를 이용하여 동일기종의 Brokers에 접속하여 외부 데이터베이스의 정보를 조회할 수 있습니다.
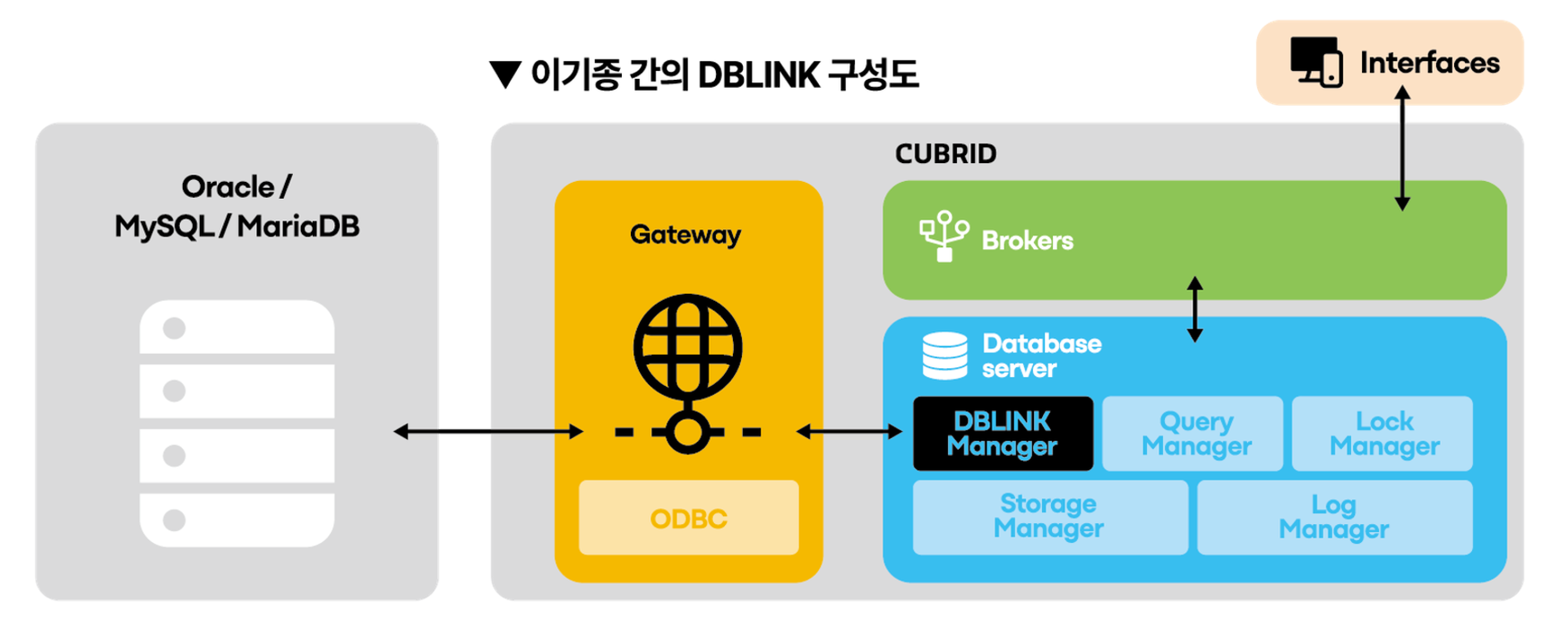
이기종 데이터베이스의 정보를 조회하기 위한 구성도를 보면 Gateway를 통해서 이기종 데이터베이스의 정보를 조회할 수 있습니다. Gateway는 연결하는 데이터베이스의 ODBC(Open DataBase Connectivity) 드라이버를 이용하고 있습니다.
분산처리(Sharding)
대용량 데이터 분산 처리를 위한 CUBRID SHARDING
- 기존 응용의 변경을 최소화하기 위한 미들웨어 형태로서, 흔히 사용되는 JDBC나 CUBRID C API인 CCI를 이용하여 투명하게 sharding된 데이터에 접근할 수 있습니다.
- 힌트를 이용하여 실제 질의 수행할 shard를 선택하는 방식으로, 기존 사용하던 질의에 힌트를 추가하여 사용할 수 있습니다.
- 일부 트랜잭션의 특성을 보장합니다.
CUBRID SHARD는 응용 프로그램과 물리적 또는 논리적으로 분할된 shard의 중간에 위치하는 미들웨어(middleware)로서, 동시에 다수의 응용 프로그램과의 연결을 유지하며, 응용의 요청이 있는 경우 적절한 shard로 전달하여 처리하고 결과를 응용에 반환하는 기능을 수행합니다.
CUBRID SHARD middleware는 broker/proxy/CAS 세 개의 프로세스로 구성되며, 각 프로세스의 간략한 기능은 아래와 같습니다.
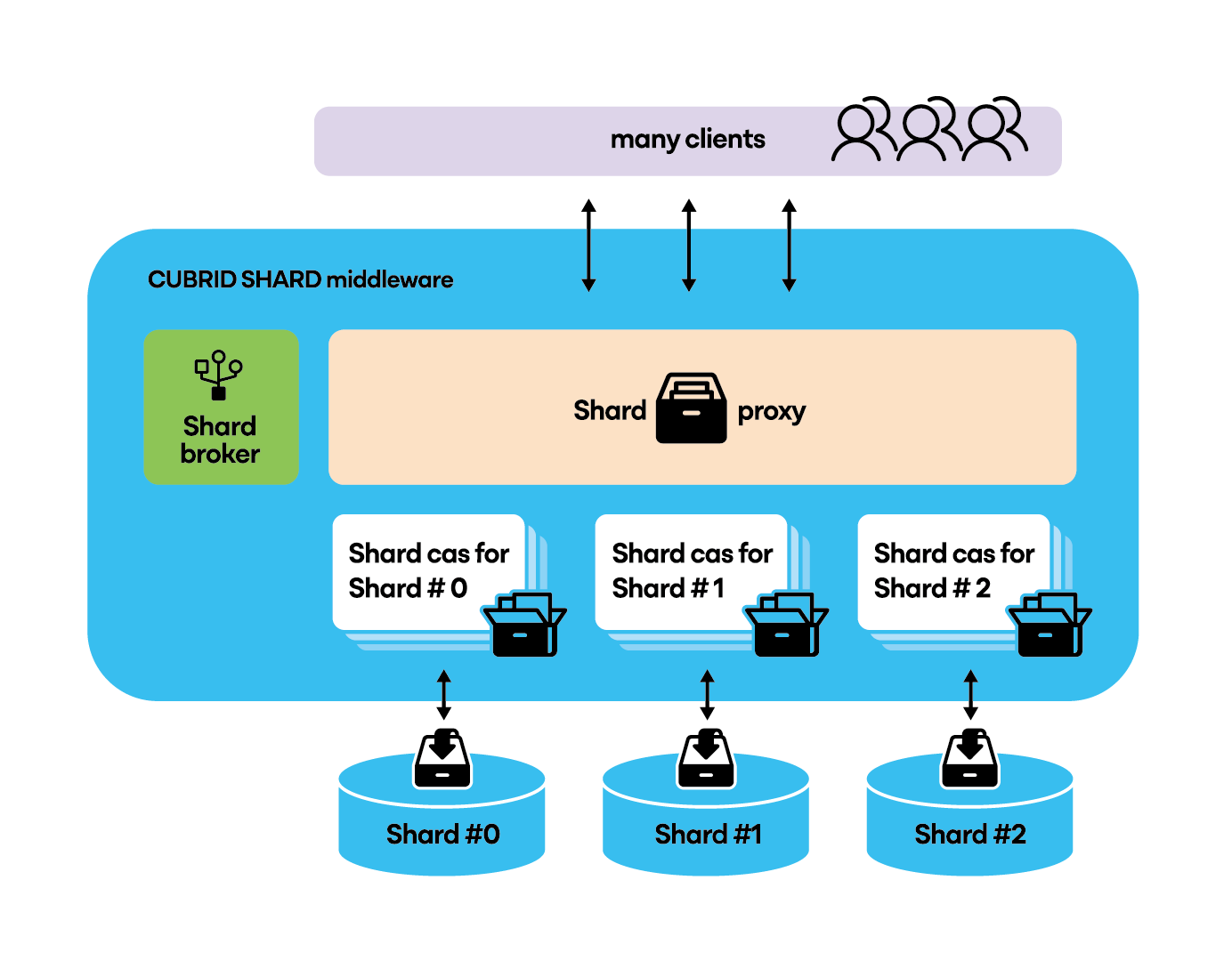
- broker
• JDBC/CCI등 드라이버로부터의 최초 연결 요청을 수신하고, 수신된 연결 요청을 부하 분산 정책에
따라 proxy로 전달
• proxy프로세스와 CAS 프로세스의 상태 감시 및 복구
- proxy
• 드라이버로부터의 사용자 요청을 CAS로 전달하고, 처리한 결과를 응용에 반환
• 드라이버 및 CAS와의 연결 상태 관리 및 트랜잭션 처리
- CAS
• 분할된shard DB와 연결을 생성하고, 그 연결을 이용하여 proxy로부터 수신한 사용자
요청(질의)를 처리
• 트랜잭션 처리
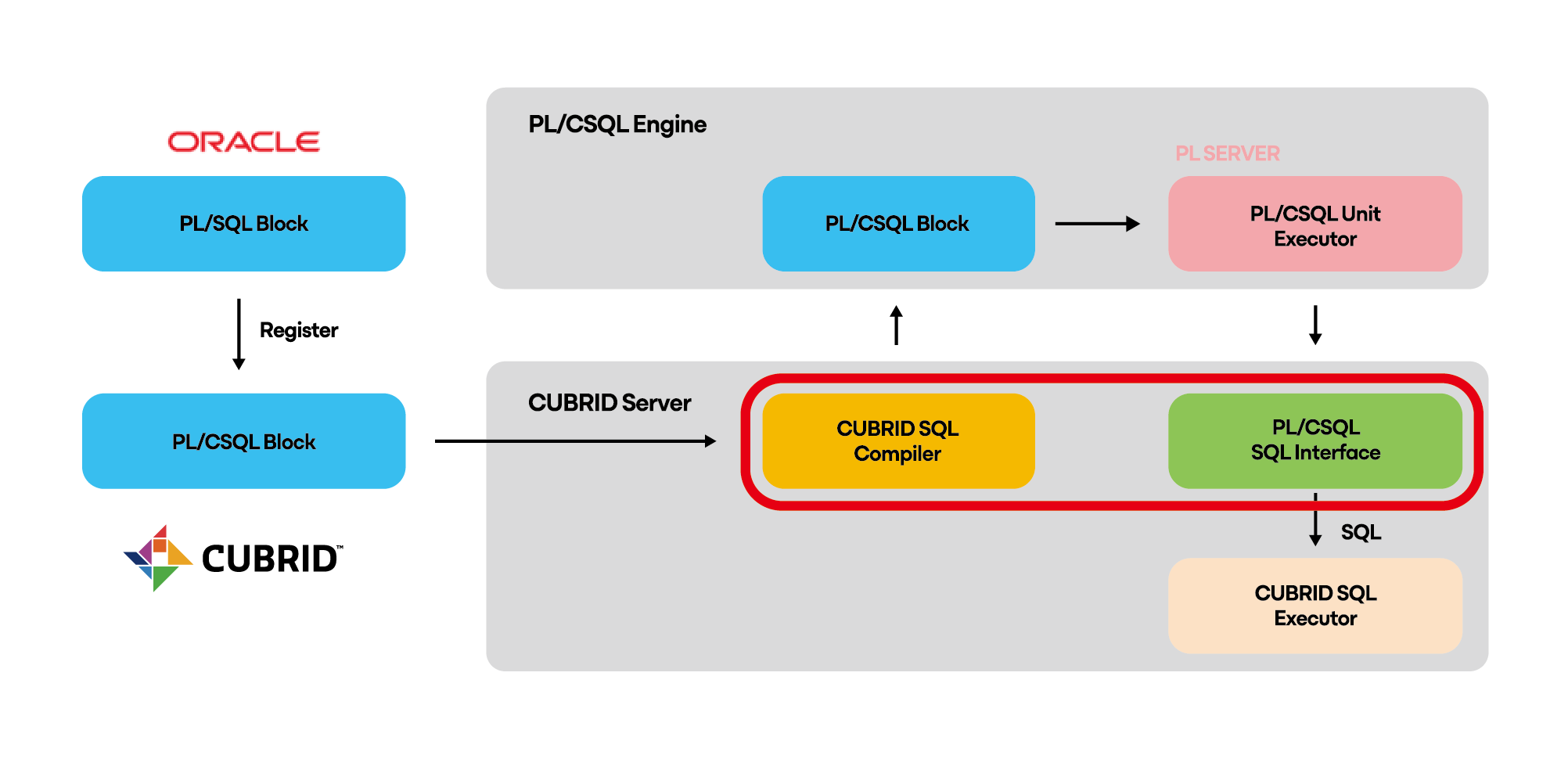
PL/CSQL
SQL 확장 프로그래밍 언어 PL/CSQL
PL/CSQL은 CUBRID에서 지원하는 저장 프로시저 및 저장함수를 작성하고 수행하는 프로그래밍 언어이며, Oracle의 PL/SQL과 호환성을 제공합니다.