
* HA 다중화 구성에서 loadBalance를 활용해 읽기 분산해 보기
먼저, CUBRID HA와 loadBalance를 잘 이해할 수 있도록 CUBRID HA 특징과 CUBRID Broker의 특징에 대해 정리해 본다.
CUBRID HA는 마스터 노드(master node), 슬레이브 노드(slave node), 레플리카 노드(replica node)로 나눌 수 있다.
- 마스터 노드 : 액티브 서버를 사용한 읽기, 쓰기 등 모든 서비스를 제공한다.
- 슬레이브 노드 : 스탠바이 서버를 사용한 읽기 서비스를 제공하며 마스터 노드 장애 시 failover가 일어난다.
- 레플리카 노드 : 스탠바이 서버를 사용한 읽기 서비스를 제공하며 마스터 노드 장애 시 failover가 일어나지 않는다.
CUBRID Broker의 ACCESS_MODE는 RW(Read Write), RO(Read Only), SO(Standby Only)로 나눌 수 있다.
- RW : 읽기, 쓰기 서비스를 제공하는 브로커이다. 일반적으로 액티브 서버에 연결하며, 연결 가능한 액티브 서버가 없으면 일시적으로 스탠바이 서버에 연결한다.
- RO : 읽기 서비스를 제공하는 브로커이다. 가능한 스탠바이 서버에 연결하며, 스탠바이 서버가 없으면 액티브 서버에 연결한다.
- SO : 읽기 서비스를 제공하는 브로커이다. 스탠바이 서버에 연결하며, 스탠바이 서버가 없으면 서비스를 제공하지 않는다.
이 외에 레플리카로 접속 할 수 있는 파라미터인 REPLICA_ONLY가 존재한다.
- REPLICA_ONLY : 레플리카 서버에 접속된다. 이 때의 ACCESS_MODE 값이 RW이면 레플리카 DB에도 쓰기 작업을 수행할 수 있고 이를 허용하지 않으려면 ACCESS_MODE 값을 RO로 설정해야 한다.
또한 CUBRID 브로커에서 QUERY의 종류를 구분하지 않기 때문에 읽기 부산을 위한 브로커에는 SELECT QUERY 만을 수행해야 한다.
이제 마스터-슬레이브-레플리카로 구성 되어 있을 때 loadbalance 읽기 부하 분산을 어떻게 할 수 있을지 살펴본다.
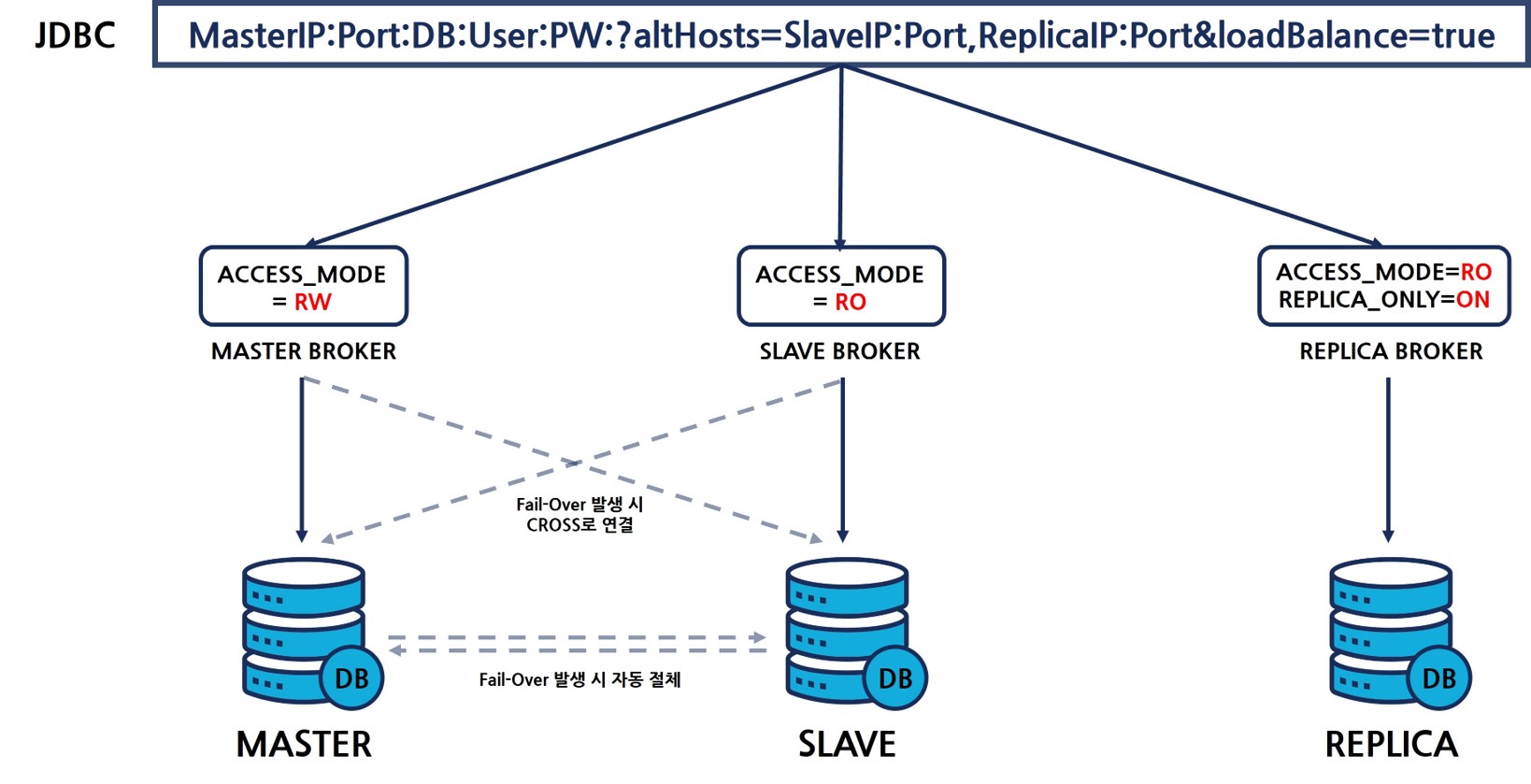
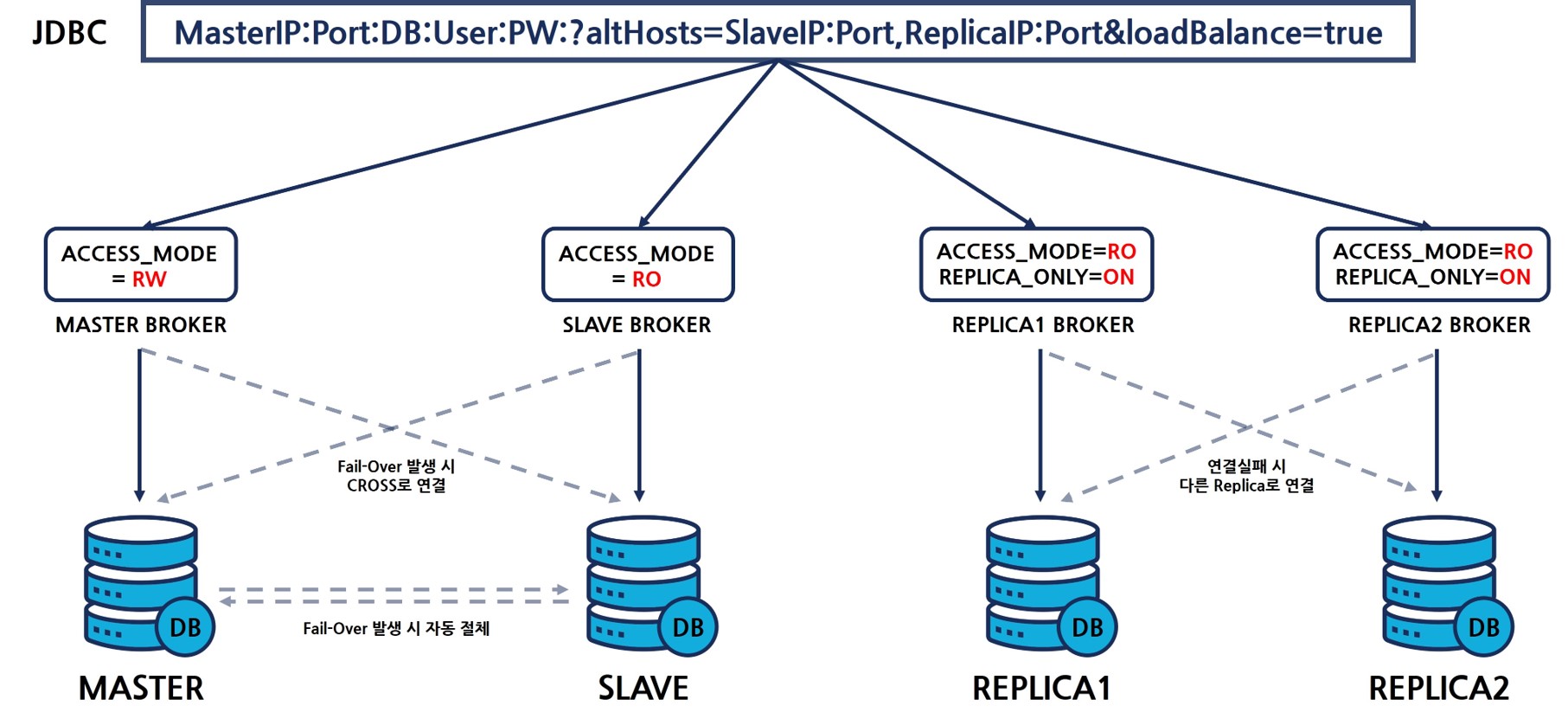
위 그림과 같이 마스터 브로커는 ACCESS_MODE=RW로 설정하여 기본적으로 마스터에 연결되도록 하고, 슬레이브브로커는 ACCESS_MODE=RO로 설정하여 슬레이브에 연결되도록 한다.
(이 때 주의할 점은 마스터, 슬레이브 노드에 부하분산을 위한 브로커는 별도 구성을 해야한다는 점이다. 기본적으로 RW브로커는 마스터, 슬레이브 양 쪽에 구성이 되어 있어야 한다.)
레플리카의 경우 REPLICA_ONLY=ON으로 설정하고, ACCESS_MODE=RO로 설정하여 레플리카 서버에만 접속을 허용하되, 쓰기 작업은 허용하지 않는다.
이 때 마스터 노드 액티브 서버의 장애 발생으로 DB 프로세스가 Down되면 fail-over가 발생되어 기존의 슬레이브 노드가 마스터 노드로 변경된다.
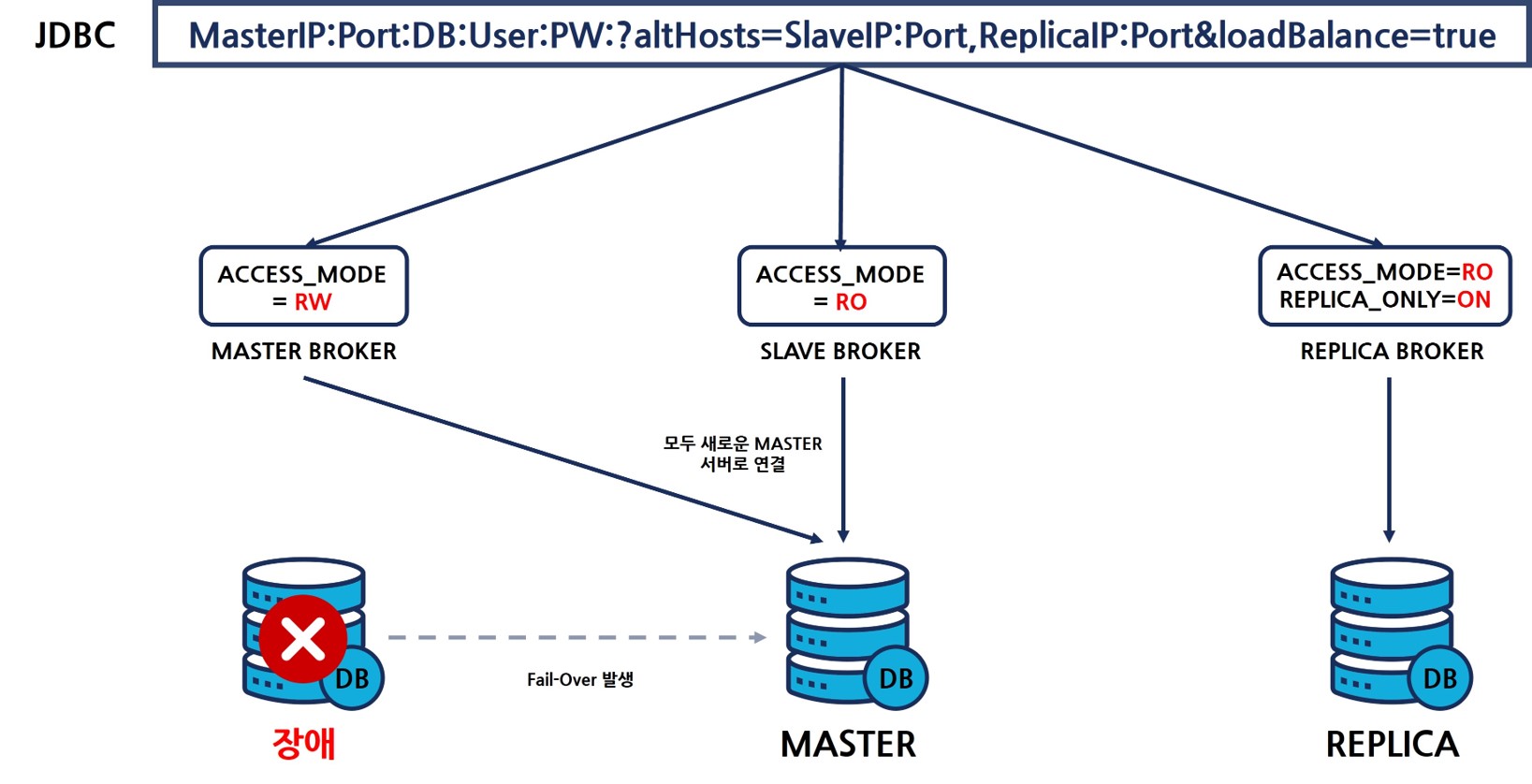 위와 같이 기존 마스터 노드였던 1번 서버에 장애가 발생되더라도, 새로운 마스터 서버(기존 슬레이브)로 연결이 되어 서비스가 정상적으로 동작한다.
위와 같이 기존 마스터 노드였던 1번 서버에 장애가 발생되더라도, 새로운 마스터 서버(기존 슬레이브)로 연결이 되어 서비스가 정상적으로 동작한다.
이 때 접속량이 기존의 두 배로 발생될 수 있기 때문에 이를 고려하여 각 DB의 max_clients를 설정해야 한다.
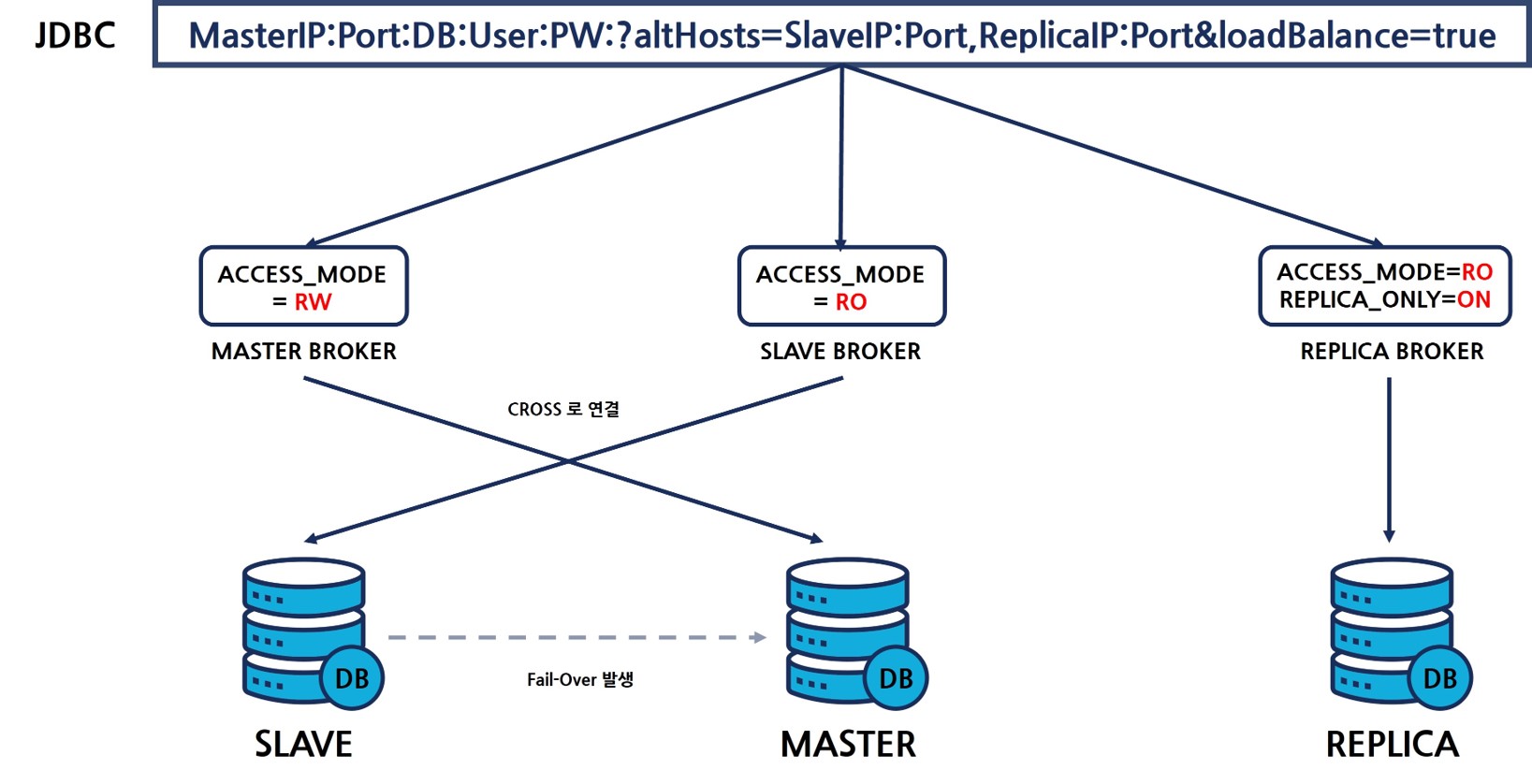
위와 같이 기존에 마스터 노드였던 1번 서버의 DB 프로세스가 정상적으로 올라온다면, 슬레이브 노드로 상태가 변경되며, 기존 구성과는 브로커-노드가 CROSS(교차)로 연결 된다.
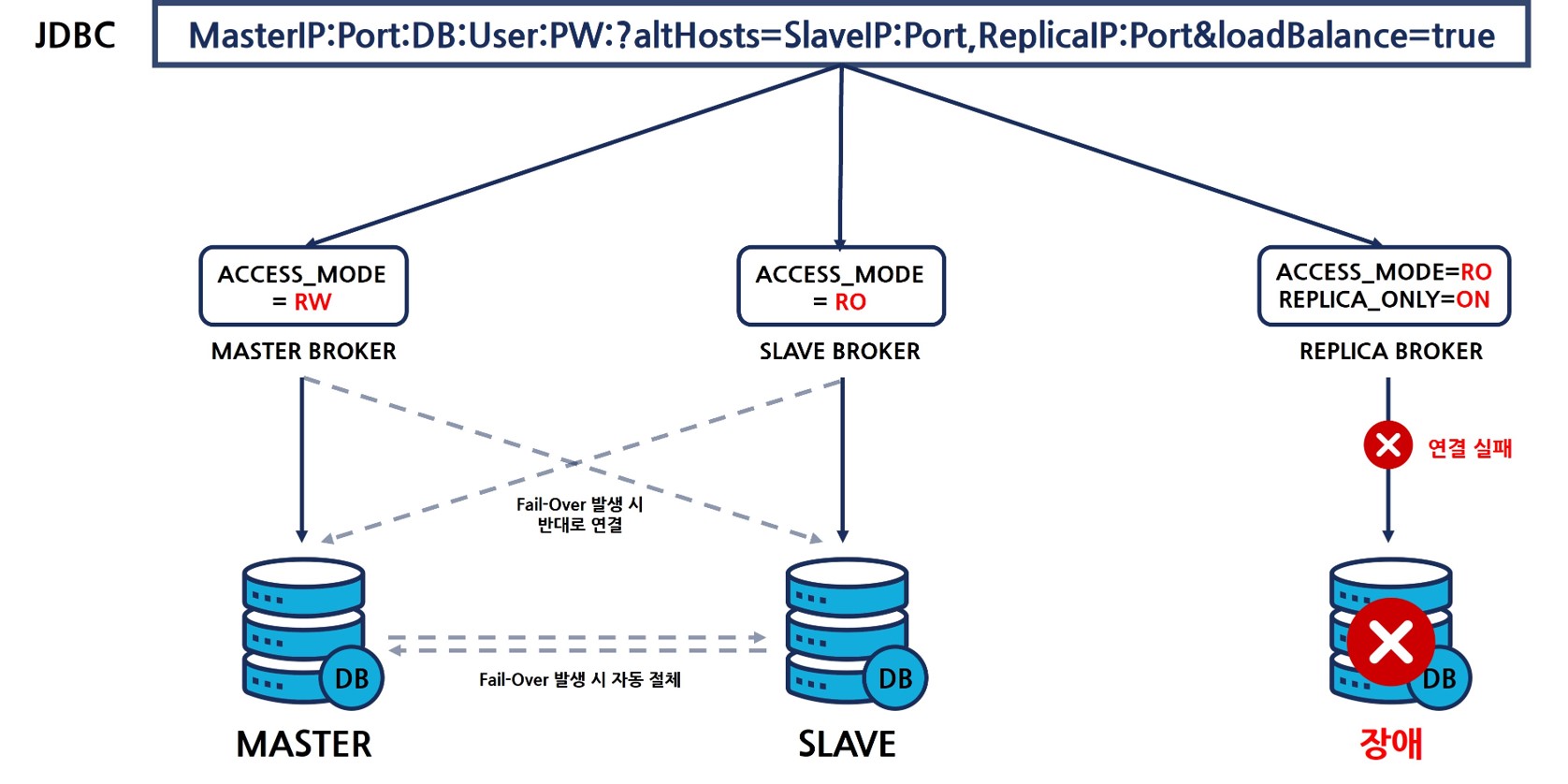
다만 이 구성에서 고려해야할 점은 REPLICA_ONLY를 설정해둔 경우 레플리카 노드 외에 다른 노드로는 접속 시도를 하지 않기 때문에 레플리카 노드에 장애가 날 경우 서비스 안정성에 문제가 있을 수 있다는 점이다.
레플리카 노드의 장애에 대비하여 레플리카 노드 역시 다중화 할 수 있다.
위와 같은 구성에서는 어떤 서버에서 장애가 발생하더라도, 서비스 안정성을 보장할 수 있으며 읽기 부하 분산도 가장 이상적으로 가능하다.
위 구성에서 각 레플리카 노드의 databases.txt 내 db-host는 각각 자신을 우선순위로 두어야 의도에 맞게 사용할 수 있다. REPLICA1의 경우 REPLICA1:REPLICA2로 설정하고, REPLICA2의 경우 REPLICA2:REPLICA1로 설정 하여야 한다.
각 노드의 databases.txt는 아래와 같이 되어야 한다.
| 노드 | 마스터 | 슬레이브 | 레플리카1 | 레플리카2 |
| db-host | 마스터:슬레이브 | 마스터:슬레이브 | 레플리카1:레플리카2 | 레플리카2:레플리카1 |
이렇게 CUBRID HA는 여러가지 구성을 유동적으로 제공하기 때문에 안정성과 성능 모두 만족할 수 있도록 각 사이트에 맞는 구성을 고려하면 좋다.
참고 매뉴얼
- CUBRID HA 구성 형태 : https://www.cubrid.org/manual/ko/11.3/ha.html#id32
- 브로커 모드 : https://www.cubrid.org/manual/ko/11.3/ha.html#broker-mode
- HA 관련 환경 설정 : https://www.cubrid.org/manual/ko/11.3/ha.html#ha-configuration
 DBMS와 효과적인 SQL 처리
DBMS와 효과적인 SQL 처리







